

发问:前几天,不管在中国如故在好意思国,你有莫得刷到过一家中国公司,作念 AI 的,叫 DeepSeek?
昨天刚开完会,公司一个小伙伴已而来精神了,说:
"欸,阿谁前几天很火的 DeepSeek 果真出 APP 了。"
一搜,还真有。
真低调。
可低调的背后,是连气儿刷了中国的屏,还刷了好意思国的屏的爆火。
2025 刚运行那几天,国内已而出了个热搜:
"雷军千万年薪,挖角 DeepSeek 的中枢盘考员,95 后 AI 天才青娥罗福莉"。
许多东说念主在这句话里,看到了"雷军",看到了"千万年薪",看到了" 95 后 AI 天才青娥"。但其中许多关怀 AI 的东说念主,还看到了:" DeepSeek "。
因为,在更早的圣诞时间,这家中国的,作念 AI 的,致使不是大厂的公司,已而刷了好意思国的屏。
2024 年 12 月 26 日,中国的 AI 公司 DeepSeek(华文名叫"深度求索"),发布了一个最新 AI 大模子 DeepSeek-V3,并同步开源。
很快,岂论是中国的 AI 圈,如故硅谷的大佬,好意思国的新闻,都运行指摘它。
国内许多媒体喊它"中国 AI 界拼多多","国货之光"。说,它讲解了"就算算力被顽固,中国也有可能搞出很好用的大模子"。
而在海外,在硅谷,更多东说念主喊它"来自东方的深奥力量"。说,这下"好意思国从 0 到 1,中国从 1 到 N "的说法,可能要被破了 ......
这个已而横空出世的中国 AI 公司,真那么横暴吗?横暴在哪?何如作念到的?到底什么来头?
我也很好奇。这几天看了一些远程,也问了一些行业里的一又友。越了解,我越有一种嗅觉:
刷屏好意思国的 DeepSeek,不一定"深奥",但确乎有点智谋。

"来自东方的深奥力量"
发问:当好意思国在刷屏聊这家公司的时候,都在聊什么?
抛开各式一会儿"战抖",一会儿"难以置信"的那些心思不说,事实说来说去,偶而即是 4 件事。
领先,性能,吓东说念主的好。
DeepSeek 的大模子,许多科目在跑分测试中,都一举独特了许多头部的开源模子。
淌若单看"理科",比如代码编写和数学运算方面,更是径直不错上手,和公共顶尖的闭源模子掰手腕。
比如 OpenAI 的 GPT-4o,Meta 的 LLama-3.1-405B,阿里 Qwen2.5-72B......
这样强,价钱,还吓东说念主的低。
东说念主家好意思国的大模子扛把子,比如 Claude 3.5 Sonnet,API 价钱是每百万输入 token3 好意思元。国产的 DeepSeek-V3 呢?优惠狠起来,只须 0.1 元东说念主民币。
这样恐怖的性价比,何如作念到的?
梁文锋曾在暗涌的采访中说:"咱们的原则是不贴钱,也不赚取暴利。这个价钱亦然在成本之上略微有点利润。"
吓东说念主的性价比背后,是低得更吓东说念主的成本。
先偶而看个账单:
DeepSeek-V3 的预造就历程,花了557.6 万好意思元,消耗了280 万GPU 小时,2048 块GPU,况兼如故英伟达针对中国阛阓的低配版:H800 GPU。
那别东说念主呢?许多财经新闻指出,OpenAI,谷歌,Meta,都花了数亿,致使数十亿好意思元。
而 OpenAI 的早期成员 Andrej Karpathy 在外交平台上说:"要作念到这种水平,往往需要3080 万GPU 小时,和16000 块GPU。"
280 万,2048 块,几百万好意思元。
3080 万。16000 块。几亿致使几十亿好意思元。
径直差出 1 个零,致使几个零。
难怪 Meta AI 盘考科学家田渊栋发文说:"对 DeepSeek-V3' 极有限的预算 ' 和 ' 建壮的施展 ' 深感惊喜。"
关联词,到这里,依然还不是让他们最"惊"的。
好意思国的 CNBC 主播在新闻里说:"这家公司的大模子,在许多方面都不输于 Meta 的 LLaMa 3.1 和 OpenAI 的 GPT 4o,趁机说一下,这些都是最新最强的模子 ...... 况兼,一又友们,别忘了这个事实:这家公司来自中国。"
超高性能,超廉价钱,超低成本,如故来自中国的 AI 公司。
很快,在硅谷,DeepSeek 运行被这样拿起:
"来自东方的深奥力量"。

"小院高墙"
这个已而横空出世的中国 AI 公司,到底,什么来头?
是不是,背后有妙手?
OpenAI 的前战术垄断 Jack Clark 就曾说:DeepSeek "雇佣了一批深奥莫测的奇才"。
而 DeepSeek 首创东说念主梁文锋在一次采访里对此的回话是:"并莫得什么深奥莫测的奇才。都是一些 Top 高校的应届毕业生、没毕业的博四、博五实习生,还有一些毕业才几年的年青东说念主。"
那,是不是,背后有本钱?
毕竟,作念大模子,从来都是少数东说念主的游戏。
有新闻透露,在许多无为东说念主都还没传说过 AI 的 2019 年,DeepSeek 就一经囤了越过 1 万张的英伟达显卡,用于算力基建了。
真横暴。但是,有越过 1 万张,就足以让 DeepSeek 有上风吗?光看 2024 年一年,领有的等效 H100GPU 数目,Meta,是 55 万 -65 万,微软,是 75 万 -90 万。谷歌,更是 100 万 -150 万 ......
东说念主,钱,都莫得什么绝顶的。那,东方,还有什么西方莫得的?
"小院高墙。"
这个 2018 年由好意思国智库残忍的科技防御策略,养殖出来的新闻,要道词基本都长这样:
管制,禁运,顽固,实体清单 ......
在好意思国 CNBC 的一个采访中,一位连线巨匠在聊起 DeepSeek 时说:
"领略,他们莫得使用最新的芯片,也莫得那么大的算力,他们致使在这方面没何如费钱,但他们却成就了一个不错和 OpenAI 和 Meta 的模子竞争的模子。"
"他们是在哪个场地作念得这样好呢?"
许多东说念主,运行连夜翻技巧文档。
是的。被称为"来自东方的深奥力量"的 DeepSeek,在最中枢的技巧上,却极少都莫得玩深奥:
他发布的大模子,都是开源的。
每一步,何如作念的,什么旨趣,致使代码,都写在公开的技巧文档里。
所有东说念主,粗率看。

"技巧文档"
DeepSeek 的技巧文档,一共 53 页。
打开,不是长这样:
即是长这样:

啊?这何如看?
我理解。我相识。这样一份文档,关于大多量无为东说念主来说,确乎难啃。
好在,许多技巧大牛,一经连夜划了要点。
比如,最常见的这段:
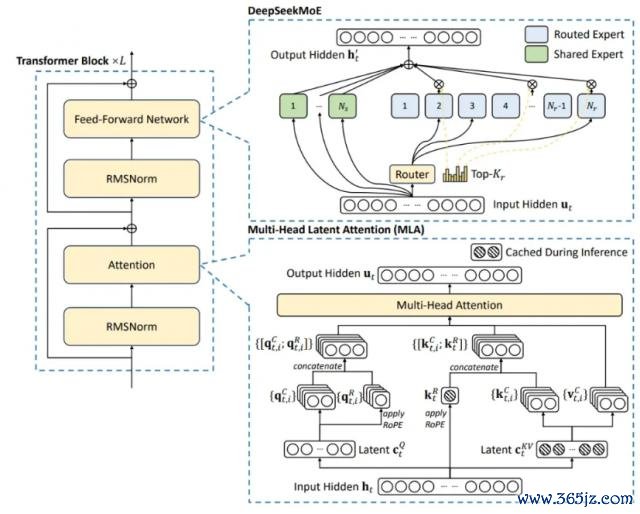
这收成于弃取了 Multi-head Latent Attention ( MLA ) 和 DeepSeek MoE 架构,已矣了高效的推理和经济高效的造就。又引入了扶持失掉目田负载平衡策略和多 token 瞻望造就野心,耕种了模子性能。同期,在 14.8 万亿个高质地 token 上进行了预造就时,通过监督微和谐强化学习阶段充分挖掘了自后劲。
看着如故太干?没事儿,再划成 3 个要道词:
MoE,MLA,无扶持失掉的负载平衡策略和多令牌瞻望造就野心。
这,即是要看懂 DeepSeek 的"深奥力量",至少,需要看懂这 3 个词。
我争取,用无为话,帮你把它们重新说一遍。
我猜,听完你会认为很眼熟。
从那里提及呢?
就从,你对大模子的条目提及吧。

"深奥力量"
发问:这两年,你有莫得用过什么 AI 大模子?
比如,好意思国的 ChatGPT?中国的文心一言 ? 通义千问 ?......
你用它的时候,都对它有什么期待?
至少,我问它个什么,它的回答得靠谱吧?靠谱以外,一个回答不行让我等上 1 分钟吧?......
又快,又好。
这,即是一个好的大模子产物,至少要作念到的 2 件事。
而这 2 件事,传到作念大模子产物的技巧巨匠的耳朵里,就会自动被翻译成另外 2 个词:
大模子的复杂度,大模子的推理后果。
什么是复杂度?至少,这个大模子的脑子得阔气智谋,能支吾阔气多,阔气复杂的问题。
脑子要智谋,要多几根"筋"。大模子要智谋,就得多几亿个"参数"。
此次发布的 DeepSeek-V3 大模子,参数就有 6710 亿个。
真多。然而,这样多"脑筋"一都动,得多远程啊?
确乎远程。是以,得烧钱,买卡,堆算力 ......
但是,你都看见了。DeepSeek 没这样干。它们干了许多其它的。
其中,最常被东说念主提到的,是这 3 件 :
第一,把一堆"巨匠"给分开。
念念象一下,大模子,就像一个巨匠大本营。为了能尽可能地帮你干各式活儿,内部防备了各式鸿沟的巨匠。
每次你一片活儿,就要呼啦啦地召唤这个巨匠大本营。荒谬劳师动众。
DeepSeek,作念了极少优化:把巨匠们比物连类,每次有活儿,只喊其中一组相应的巨匠团出来就好。
这,即是 MoE 架构,也叫搀和巨匠技巧。
这样分,原来每次有活儿,得惊动 6710 亿个参数,目下只须 37 亿个参数就不错了。多省力。
真智谋。然而,一个大模子,就算调的巨匠少了,每天要干的活儿如故超等多。有莫得办法更省力?
DeepSeek 又念念到了个办法:把要干的活儿,压少一些。
比如,搞个东西,让模子不错在干活儿时,学会"握大放小"。精准到"元"就够的,就毫不精准到"毛"。大不了算完再派个巨匠,合并验算一遍。
这个东西,就叫 MLA,也叫信息过滤器。能让模子只关怀信息中的紧迫部分,不会被不紧迫的细节散播防备力。
成心思。这样一来,对算力的依赖详情又能少好多。
可 DeepSeek 依然没知足。"巨匠"和"活儿"都盘了,那中间的"派活"呢?
我能不行再搞个机制,让每个巨匠,都能被合理单干。不至于要么给我闲着,要么忙到爆炸?
于是,就有了:无扶持失掉的负载平衡策略和多令牌瞻望造就野心。
目下,再看回这 3 个词,你什么嗅觉:
MoE,MLA,无扶持失掉的负载平衡策略和多令牌瞻望造就野心。
分巨匠,压活儿,合理单干。
嗯,很智谋。然而,不是在说"深奥力量"吗?
这算什么深奥力量?

"工程"
发问:何如才算"深奥力量"?
能突破"小院高墙"?能冲突"海外从 0 到 1,中国从 1 到 N "的不雅念,带来颠覆性鼎新?
淌若是这个圭臬,那 OpenAI 首创东说念主奥特曼,可能认为,不算。
在 DeepSeek 大模子发布后,他曾说:
" DeepSeek-V3,仅仅在复制已知有用的东西。但当你不知说念某件新奇、有风险且穷苦的事情是否会告成时,去作念他是极其穷苦的。"

为什么这样说?是不是在酸?是不是在内涵?
这样,不如咱们先浅近倒个带:
你说,"把一堆‘巨匠’给分开",算不算鼎新?
你说,"把要干的活儿,压少一些",算不算鼎新?
你说:"把活儿分配得合理些",算不算鼎新?
或者更径直极少:"用几百万的成本,作念到东说念主家花几十亿才作念到的事",算不算鼎新?
看另一个技巧大佬,驰名 AI 博主 Tim Dettmers,对 DeepSeek 的评价。

他说:"这是资源为止下的工程。"
他还说:"这一切看起来都那么优雅:莫得花哨的‘学术’陆续决议,只须结净的,塌实的工程。尊重。"
工程,工程。
什么是工程?
径直搜"工程",你会看到这个界说:
"工程是一个具有纪律运行和收尾时刻的任务,需要使用一种或多种资源,并由多个彼此独处、彼此相干、彼此依赖的行径组合。"
但淌若,当你收到客户投诉"收到的薯片有包装是空的"时,别东说念主会和你说:
"装监控","作念视频识别",或者,"花 100 万,研发一条新的活水线" ......
但工程师,可能会和你说:
"花 100 块,在目下的活水线终末,装个大吹风机,吹出刚好能吹跑空包装的就行。"
工程,即是就算在有限资源下,也一定要把事作念成,况兼还要把后果作念到最高。
回看 DeepSeek 的鼎新,有些,确乎是始创。比如,无扶持失掉负载平衡,就来自 DeepSeek 八月的论文。
也有些,是"在已有的活水线上装上吹风机"。比如,优化前就一经存在的 MoE,MLA......
花 100 万作念个新活水线,花 100 块加个大吹风机。
从 0 到 1,从 1 到 N。
刷屏好意思国的 DeepSeek,不一定深奥,但确乎智谋。
恭喜。
也祝贺,2025 年,更多的"从 1 到 N ",和,"从 0 到 1 "。
* 个东说念主不雅点,仅供参考。
编缉 / 尤安 剪辑 / 二蔓 版面 / 黄静现金九游体育app平台